이번 글에서는 나의 환경에 맞는 Apache Spark과 Hadoop 클러스터 구축에 대한 방법을 소개하겠다
하드웨어 환경 - SingleBoard Computer(라즈베리파이, 라떼판다) 사용


- 클라우드 서버를 사용해서 클러스터를 구축할 수 있지만, 주기적으로 비용이 발생하고 학생이라 비용 문제로 기존에 있는 SBC(Single Board Computer)를 사용해 직접 클러스터를 구축하였다
- 클러스터 케이스 같은 경우 직접 모델링 해서 학교에 있는 3D 프린터기를 사용하여 출력해서 케이스를 만들어줬다
- (원래는 한옥 모양으로 만들었으나, 발열 문제로 제거했음)
네트워크는 공유기를 사용해서 클러스터 노드 끼리 같은 내부 망을 사용하도록 했고,
랜선 허브를 통해 유선으로 연결하였다.


아직 미숙한 클러스터 구축이지만, 발전하고 있다고 생각한다.
서버 설정
필수 설정은 아니지만, 해두면 좋은 설정이다.
라즈베리파이와 라떼판다에 Ubuntu 22.04 LTS를 설치했기 때문에, ubuntu 기준으로 작성하겠다.
#spark 계정 생성
sudo useradd spark -m -s /bin/bash
#패스워드를 입력
sudo passwd spark
#spark 계정 root 권한 부여 및 패스워드 사용 X
sudo visudo
spark ALL=(ALL) NOPASSWD: ALL
#spark 계정으로 전환
sudo su - spark
#hostnamectl 명령어로 hostname을 각 노드별로 알기 쉽게 변경
sudo hostnamectl set-hostname spark-master-01
# /etc/hosts를 수정하여 ip 대신 hostname으로 통신이 되도록 설정
vi /etc/hosts
ex)
192.168.1.10 spark-master-01
192.168.1.11 spark-worker-01
192.168.1.12 spark-worker-02
192.168.1.13 spark-worker-03
192.168.1.14 spark-worker-04
#ssh 통신을 했을 때, 패스워드를 요청하지 않아야 하기 때문에, ssh key 전송
#마스터 노드에서 각 워커 노드마다 실행
cat ~/.ssh/id_rsa.pub | ssh spark@spark-worker-01 'cat >> ~/.ssh/authorized_keys'Java 설치
#jdk 8 설치
sudo apt install openjdk-8-jdk
#환경변수 설정
vi ~/.bashrc
#jdk가 설치된 경로를 찾아 설정
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-armhf
#환경변수 설정 저장
source ~/.bashrcSpark 설치
#원하는 버전의 Spark을 설치
wget https://dlcdn.apache.org/spark/spark-3.5.0/spark-3.5.0-bin-hadoop3.tgz
tar zxvf spark-3.5.0-bin-hadoop3.tgz
#Spark 환경변수 설정
export SPARK_HOME=/home/spark/spark-3.5.0-bin-hadoop3
#spark이 설치된 디렉토리의 conf/spark-env.sh 설정
vi conf/spark-env.sh
#java 환경변수 추가
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-armhf
#spark shell 실행
spark-shell
#spark shell을 실행하면 정상 실행일 경우
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
24/01/09 15:48:19 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://spark-master-01:4040
Spark context available as 'sc' (master = local[*], app id = local-1704782902976).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.5.0
/_/
Using Scala version 2.12.18 (OpenJDK Client VM, Java 1.8.0_392)
Type in expressions to have them evaluated.
Type :help for more information.
Spark history 서버 구성
- spark history 서버를 따로 구성해줘야한다
- spark이 설치된 디렉토리의 conf/spark-default.conf 수정
spark.history.fs.logDirectory file:///home/spark/spark-3.5.0-bin-hadoop3/history
spark.eventLog.enabled true
spark.eventLog.dir file:///home/spark/spark-3.5.0-bin-hadoop3/history- spark이 설치된 디렉토리에 history 디렉토리 생성
- sbin 디렉토리에 start-history-server.sh를 실행하면 history-server가 실행 됨
- http://ip:18080으로 접속하면 spark history 서버 web ui 접속 가능
Hadoop 설치 및 설정
#Hadoop 설치
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
tar zxvf hadoop-3.3.6.tar.gz
#환경변수 설정
vi ~/.bashrc
export HADOOP_HOME=/home/spark/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-armhf
export PATH=$PATH:$JAVA_HOME/bin
export PDSH_RCMD_TYPE=ssh
export SPARK_HOME=/home/spark/spark-3.5.0-bin-hadoop3
export PATH=$PATH:$SPARK_HOME/bin
#하둡이 설치되어 있는 디렉토리의 etc/hadoop/hadoop-env.sh 설정
vi etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-armhf- 이제 hadoop이 설치된 디렉토리에서 hadoop 설정들을 해줘야한다
- hadoop이 설치된 디렉토리를 hadoop이라고 가정하고 진행하겠다
- hadoop/etc/hadoop/core-stie.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://spark-master-01:9000</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>spark</value>
</property>
</configuration>- hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/spark/hadoop-3.3.6/dfs/data</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/spark/hadoop-3.3.6/dfs/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/home/spark/hadoop-3.3.6/dfs/namesecondary</value>
</property>- yarn-site.xml
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>spark-master-01:8188</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>spark-master-01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>- hadoop/etc/hadoop/workers 파일에 워커 노드들의 ip 주소나 hostname을 넣어줘야한다
- 앞에서 hosts에 ip와 hostname을 매칭시켜놓았기 때문에, hostname을 넣어줘도 된다
spark-worker-01
spark-worker-02
spark-worker-03
spark-worker-04Hadoop 실행
- hadoop/bin/hdfs를 실행하면 된다
- 처음 실행할때, hdfs를 포멧해줘야한다
hdfs namenode -format- start-dfs.sh를 실행해서 hdfs를 실행
hadoop/sbin/start-dfs.sh- 이제, http://ip:9870에 접속하면 hadoop 웹 ui를 볼 수 있다

- hadoop의 워커노드들의 상태를 확인할 수 있고, hdfs로 파일을 이 웹 ui를 통해 올릴 수도 있다
에러 발생 원인 및 해결
1. 워커노드 Hadoop 프로세스 실행 에러
- 정상적으로 실행이 된다면, start-dfs.sh 실행 후에, jps로 실행 중인 프로세스를 확인하면 hadoop 프로세스가 떠 있어야한다
- datanode, namenode, secondarynamenode. ResourceManager 등이 실행되고 있어야 하지만, 실행되고 있지 않아서 로그를 까봤다
- hadoop-spark-namenode-spark-master-01.log namenode 의 로그에선 /dfs/name 디렉토리의 권한이 없다고 해서
sudo mkdir -p /home/spark/hadoop-3.3.6/dfs/name
sudo mkdir -p /home/spark/hadoop-3.3.6/dfs/namesecondary
sudo mkdir -p /home/spark/hadoop-3.3.6/dfs/data
sudo chown -R spark:spark /home/spark/hadoop-3.3.6/dfs/namesecondary
sudo chown -R spark:spark /home/spark/hadoop-3.3.6/dfs/name
sudo chown -R spark:spark /home/spark/hadoop-3.3.6/dfs/data
sudo chown -R spark:spark /home/spark/hadoop-3.3.6/dfs- 이렇게 쓰기 권한을 부여해주면 된다
- name, secondaryname 디렉토리는 마스터노드에서 해주고
- data 디렉토리는 모든 워커 노드에서 해줘야한다
- 그리고 다시 start-dfs.sh를 하면, 프로세스들이 정상적으로 실행되는 것을 확인할 수 있다
2. 마스터 노드와 워커노드 연결 에러
- hadoop이 정상적으로 실행된다면 http://ip:9870로 접속하여 hadoop 웹 ui에 접속하여
- Datanodes 탭을 클릭하면 연결된 워커 노드들을 확인할 수 있다

- 하지만 이때 당시에 어떤 에러로 워커 노드들이 datanodes에 사라져서 로그를 확인해야했다

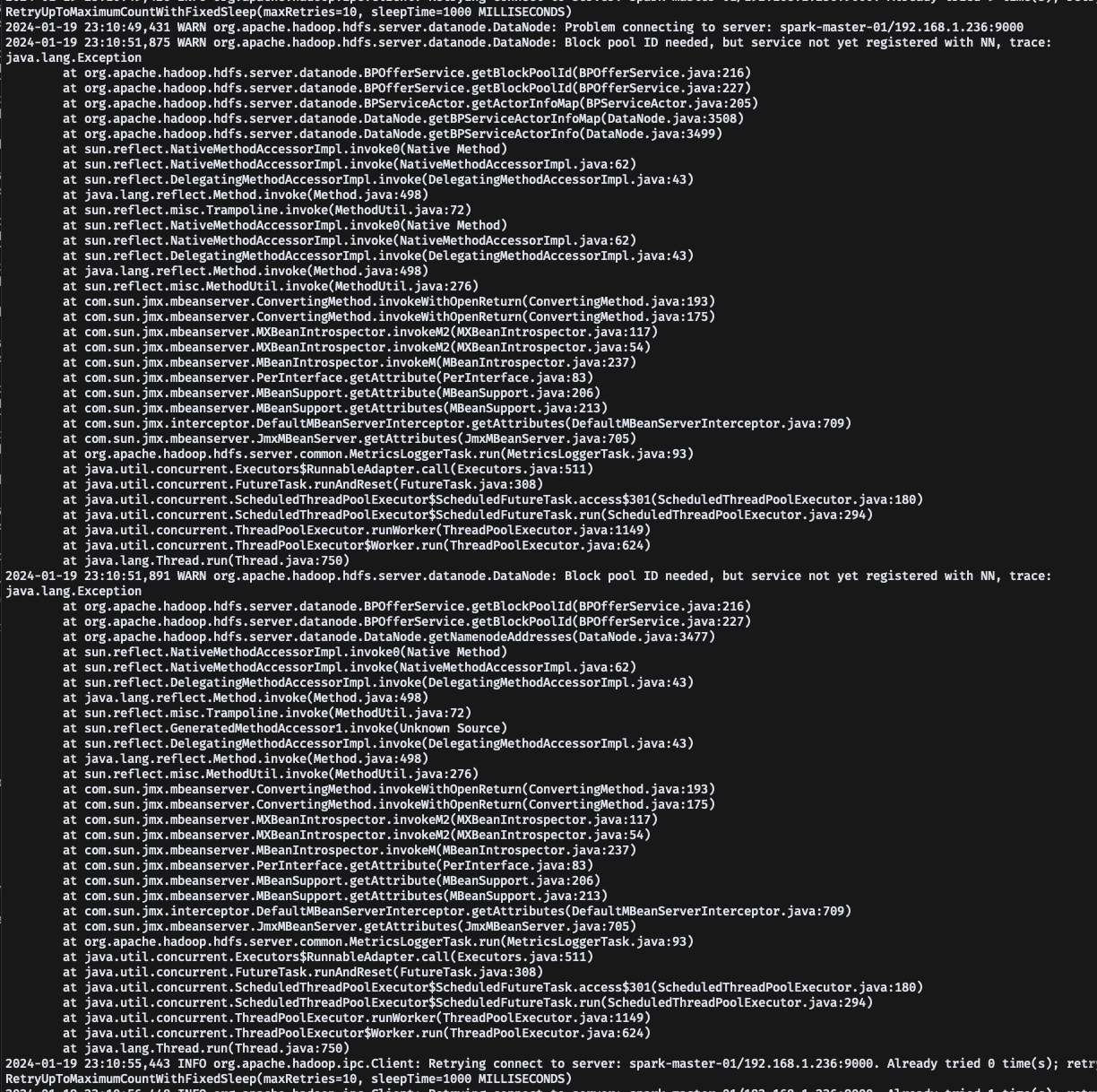

- 워커 노드의 로그를 확인해보니, 마스터 노드와의 연결이 계속 실패하고 있는 상태로 확인이 되고 있었다
- 당시에 구글링과 overflow에서 에러 원인을 찾고 있었는데, 번번히 실패하던 와 중에 overflow의 한 답변을 보고 힌트를 얻었다

- 답변의 내용은 etc/hosts에서 127.0.0.1 ip로 네임노드가 바운딩 되어서 워커노드와 연결이 안될 수도 있으니까, etc/hosts에서 127.0.0.1 부분을 제거해라
- 라는 답변이 있었고 실제로 내가 본 로그 중에서 마스터 노드의 네임노드 로그에서 비슷한 내용이 있었다

- 잘 보면 NameNode RPC up at: spark-master-02/127.0.1.1:9000 라는 로그가 보이는데, 127.0.1.1 이 아닌 내부 대역 ip에 바운딩이 되어 있었어야 했지만, 127.0.1.1 로 바운딩 된 것으로 보인다
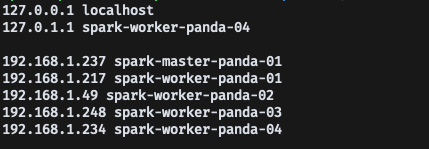
- 기존의 etc/hosts 파일 내용은 이러했는데, hadoop core-site.xml 설정에서
- ip 대신 hostname으로 바운딩 했던 설정이 있었다, 이때 192.168.1.237에서 9000 포트로 네임노드가 바운딩 되지 않고, 127.0.1.1로 바운딩 되어서 워커 노드들이 정상적으로 연결되지 않았을까? 예상했다

- 그래서 hosts에서 127.0.1.1 ip를 지워주고, hdfs format 및 hdfs 재시작을 해주니까 다시 워커노드들이 정상적으로 연결되었다

- (이때 당시 일주일 정도를 이 에러로 고생하고 있었고, 새벽 4시에 원인을 찾고 해결해서 도파민 분비가 엄청났다, 놀라운 점은 아직 hadoop 에러만 다뤘다는 점.. spark 또한 에러가 엄청 발생했다)
Spark 설정 및 실행
Spark 설정
- spark을 설정하기 위해 spark이 설치된 디렉토리로 이동한다
- conf로 이동하여 spark-env.sh.template를 spark-env.sh 복사, spark-defaults.conf.template를 spark-default.conf로 복사, workers.template를 workers로 복사하여 생성해준다
- spark-env.sh
JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
SPARK_WORKER_PORT=7178 # default: random
SPARK_WORKER_CORES=8 # default: all available
SPARK_WORKER_MEMORY=8G # default: machine's total RAM minus 1 GiB
SPARK_LOCAL_DIRS=/home/spark/spark-3.1.2-bin-hadoop3.2/local
SPARK_PUBLIC_DNS=${HOSTNAME}- JAVA의 위치를 넣어주고, 워커 노드의 포트를 고정으로 지정해줄 수 있다, 기본적인 워커 노드의 코어나 메모리를 정해줄 수 있으며 spark local 디렉토리 위치를 명시해줘야 한다
- spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir file:///home/spark/spark-3.1.2-bin-hadoop3.2/history
spark.driver.maxResultSize=4g- 로그에 대한 설정과 나 같은 경우에는 크기 관련 에러가 발생하여 maxResultSize를 4g로 설정하여 늘려줬다
- workers
spark-worker-panda-01
spark-worker-panda-02
spark-worker-panda-03
spark-worker-panda-04- Hadoop 설정 할 때와 마찬가지로 spark 또한 worker 설정을 해줘야한다
- 워커노드들의 ip나 hostname을 넣어주면 된다
Spark 실행
- spark 실행은 sbin 디렉토리의 여러가지 실행 파일이 존재한다
- 필요한 프로세스만 실행 시켜주는 것이 좋지만, 시원하게 start-all.sh 해줘도 된다
- 이제 설정이나 워커 노드들이 제대로 적용되었는지 확인하기 위해 spark web ui에 접속해서 확인해 볼 수 있다
Spark web UI
- Spark Web UI는 몇가지가 있다
Spark App UI
- spark App UI는 먼저 기본 spark-shell을 실행하고, http://spark-master노드 ip:4040으로 접속하면


- spark이 실행하는 jobs나 excutors를 time line으로 확인할 수 있다
Spark Web UI
- spark standalone web UI는 위에서 sbin/start-all.sh를 실행하고, http://spark-master node ip:8080에 접속하면 볼 수 있다
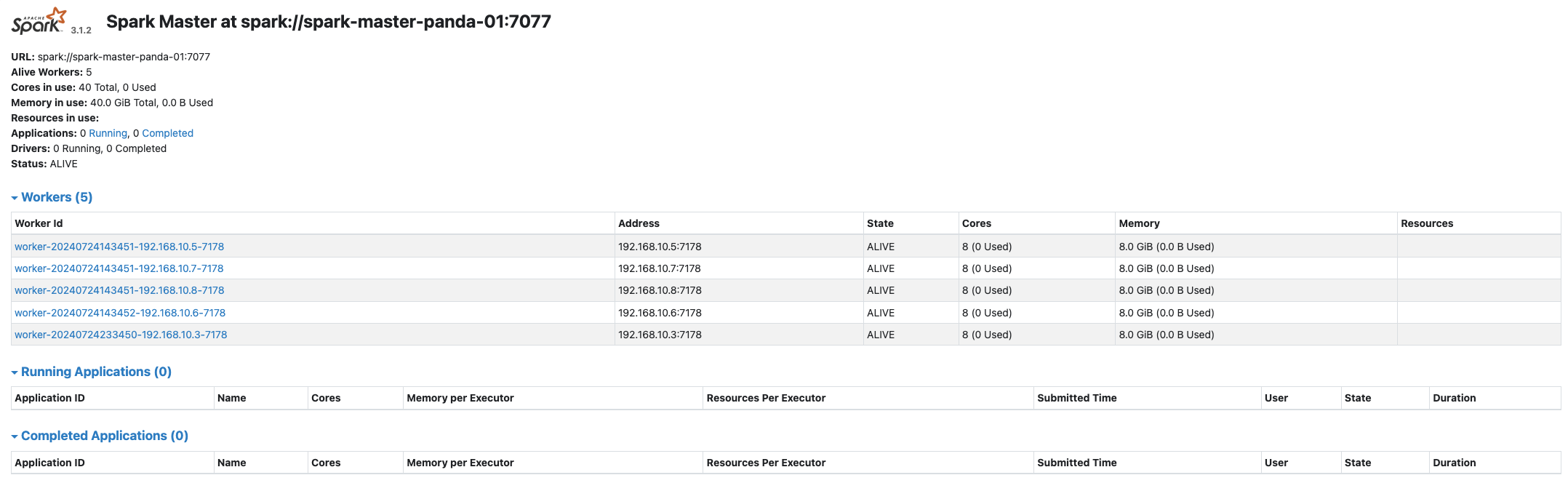
- 워커 노드들의 코어나 메모리 설정이 잘 되어 있는지 확인할 수 있으며, 코드를 실행하면 Running Applications에서 확인 할 수 있다
Spark history server Web UI
- Spark 설치된 디렉토리로 이동하여 sbin/start-history-server.sh 실행하면 history server가 실행된다
- history server Web UI는 18080 포트로 접속하면 확인할 수 있다

- Spark App 로그를 확인할 수 있다
- 다음 글에서 Spark UI에 대해 자세하게 다뤄보도록 하겠다
Spark 실행 방법
- spark은 실행할 수 있는 여러가지 방법이 존재한다
- spark-shell을 통한 스크립트 형식, zeppelin을 사용한 web notebook 방식 등이 있다
- master를 yarn으로 설정해서 hdfs와 spark을 연동하려면 관련 설정이 필요하다
- spark이 설치된 디렉토리에 conf2라는 디렉토리를 생성하고
- 그 안에 core-site.xml과 yarn-site.xml 파일을 생성한다
- core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://spark-master-01:9000</value>
</property>
</configuration>- yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>spark-master-01</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>spark-master-01:8188</value>
</property>
</configuration>- 이렇게 설정하고 spark-shell이나 zeppelin으로 실행 할 때, conf2의 디렉토리 위치를 명시해줘야한다
1. spark-shell 실행
- 먼저 spark-shell로 실행할 경우 파라미터를 줘서 환경에 맞게 실행할 수 있다

- spark-shell로 실행할때, 파라미터를 줘서 설정을 할 수 있는데, 위 같은 경우는 master 환경을 yarn, excutor memory를 4G, excutor 당 코어수 4, excutor 개수를 4개로 설정하고 spark-shell을 실행하였다
- 자신의 하드웨어 환경에 맞게 파라미터를 설정하면 된다
- scala 언어로 스크립트를 작성할 수 있다
2. Zeppelin 설치 및 실행
- web notebook 환경에서 spark을 실행하고 코드를 작성할 수 있다 (jupyter notebok와 비슷하다고 보면 된다)
- 먼저 zeppelin을 설치해준다
wget https://archive.apache.org/dist/zeppelin/zeppelin-0.10.1/zeppelin-0.10.1-bin-all.tgz
tar xvfz zeppelin-0.10.1-bin-all.tgz- zeppelin 디렉토리로 이동해서 conf/zeppelin-site.xml.template과 zeppelin-env.sh.template를 cp로 복사하여 zeppelin-site.xml과 zeppelin-env.sh를 생성해준다
- zeppelin-site.xml
<property>
<name>zeppelin.server.addr</name>
<value>0.0.0.0</value>
<description>Server binding address</description>
</property>
<property>
<name>zeppelin.server.port</name>
<value>9090</value>
<description>Server port.</description>
</property>- zeppelin-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export SPARK_MASTER=spark://spark-master-panda-01:7077 # Spark master url. eg. spark://master_addr:7077. Leave empty if you want to use local mode.
export ZEPPELIN_ADDR=0.0.0.0 # Bind address (default 127.0.0.1)
export ZEPPELIN_PORT=9090 # port number to listen (default 8080)
export PYSPARK_PYTHON=/home/spark/.pyenv/shims/python # path to the python command. must be the same path on the driver(Zeppelin) and all workers.
export PYTHONPATH=/home/spark/.pyenv/shims/python- Java 환경변수와 spark master nodet 설정, port 설정, python 환경변수 설정 등을 해줘야한다
- python 경로는 pyenv라는 python 버전을 자유롭게 변경할 수 있도록 미리 설치했다 (에러 때문에 python 버전 변경이 필요했다)
- zeppelin/bin/zeppelin-daemon restart 하면 http://master node ip:9090으로 zeppelin web UI에 접속할 수 있다

- 이렇게 Zeppelin Web UI에 접속하여 note를 생성해서 셀 별로 spark 코드를 작성하고 실행할 수 있다
- 그 전에 zeppelin interpreter 설정을 해줘야한다

- annoymous 탭을 클릭해서 interpreter 페이지에 들어간다

- create + 버튼을 눌러 새로운 interpreter를 생성할 수 있다
- interpreter name에 spark_yarn 이런 식으로 이름을 자유롭게 지어주고 interpreter group에 spark을 선택한다
- 그럼 spark shell을 실행 했을 때 파라미터로 spark shell을 실행했던 것 처럼 zeppelin에서 미리 설정한 값으로 spark 을 실행할 수 있다
- Properties 설정을 해줘야하는데, 여기에서 전부 다루기 어려우니 다음 글에서 자세한 설정에 대해 다뤄보도록 하겠다
- 나 같은 경우 spark.master를 standalone 보다 yarn으로 많이 사용하기 때문에, yarn Properties 설정한 것만 넣겠다

- 자신의 환경에 맞게 properties를 설정해주면 된다
- 이제 create note 해서 새로운 note를 만들어주면 된다
에러 발생 및 해결 방법
- 이번 에러는 정말 오래 걸렸고 구글링과 overflow에도 에러에 맞는 해결방법이 없었다
- 발생한 에러는 이러하다
Caused by: org.apache.zeppelin.interpreter.InterpreterException: Fail to bootstrap pyspark
at org.apache.zeppelin.spark.PySparkInterpreter.open(PySparkInterpreter.java:105)
at org.apache.zeppelin.interpreter.Lazy0penInterpreter.open(Lazy0penInterpreter.java:70)
... 8 more
Caused by: java.io.I0Exception: Fail to run bootstrap script: python/zeppelin_pyspark.py
- 에러 원인이 zeppelin과 spark에서 지원하는 python 버전을 맞춰서 환경변수 설정을 해줬어야 했다
- 처음 ubuntu를 설치했을 때, 설치된 Python 3.11 버전으로 환경변수를 설정하고 사용했다가 에러가 발생했는데,
- 3.6 버전으로 맞춰주니까 에러가 해결되었다
- python 버전은 pyenv를 사용해서 유동적으로 버전을 변경할 수 있게 해주었다
sudo apt update
sudo apt install -y make build-essential libssl-dev zlib1g-dev \
libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm \
libncurses5-dev libncursesw5-dev xz-utils tk-dev libffi-dev \
liblzma-dev python3-openssl git
git clone https://github.com/pyenv/pyenv.git ~/.pyenv
export PYENV_ROOT="$HOME/.pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init --path)"
pyenv install 3.6.15
pyenv global 3.6.15- 이렇게 pyenv를 사용해서 python을 3.6 버전으로 변경해주고, pyenv로 환경변수 설정을 해주면 된다
- 또한, spark 3.1.2 버전을 zeppelin에서 공식적으로 지원하기 때문에 spark 또한 3.1.2 버전으로 변경해줘야한다
- 이렇게 버전을 변경하면 zeppelin에서 %python과 %pyspark를 사용할때, 에러가 발생하지 않을 것 이다
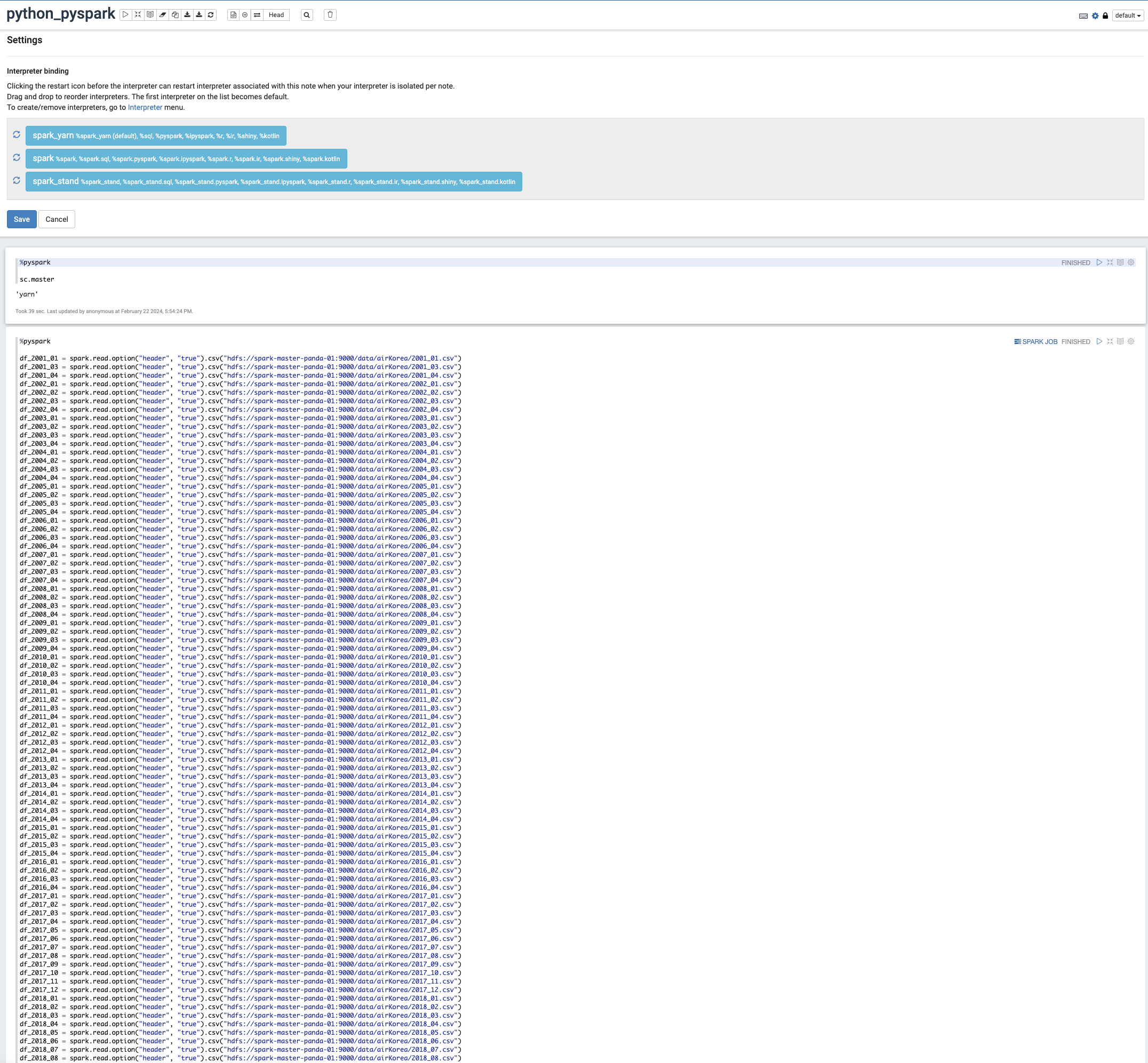
- 우상단에 톱니 모양 아이콘을 클릭하면 전에 설정한 interpreter들이 보이고, 실행 우선순위를 정할 수 있다
- 전에 hadoop 설정을 끝내고, hdfs까지 모두 정상 작동했다면, master를 yarn으로 설정한 spark을 실행할 수 있다
- %pyspark으로 입력하고 코드를 실행하면 python 기반의 pyspark으로 작동한다, default는 scala 언어로 실행된다 (Spark은 JVM 위에서 돌아가기 때문에 Scala가 더 빠르다는 논문을 봤는데, 데이터 크기나 노드 개수에 따라 다르기 때문에 편한 언어로 작성하는 게 좋다고 생각한다)
- python_pyspark 노트에서 작성한 코드는 yarn으로 master를 설정했기 때문에, hdfs에서 데이터를 가져올 수 있다(hdfs로 하지 않고 일반 file 경로로 데이터를 가져오려면 모든 노드의 같은 위치에 파일이 있어야 한다, 단일 노드에서 실행한다면 상관 없음)
- Spark RDD, DataFrame 와 같은 프로그래밍에 대해서는 다음 포스팅에서 다루도록 하겠다
- DataFrame 방식으로 코드를 작성하고 실행하면, SPARK JOB 탭에서 Spark가 실행한 Job들을 확인할 수 있다


- Excutor들이 언제 적재되었는지, Spark 스케줄링 구조에 대해 자세하게 볼 수 있는 UI를 제공한다
포스팅을 마치며
- 이번 포스팅은 나의 개발 블로그 첫 글이자, 데이터엔지니어를 준비하기 위해 하드웨어를 사용하여 클러스터를 구축하고, 분산 컴퓨팅 시스템을 구축한 경험을 바탕으로 작성한 글이다
- 내가 처음으로 Hadoop과 Spark를 적용하려고 했을 때, 삽질을 1달 정도 했기 때문에 최종적으로 2달이 걸려서야 적용할 수 있었다
- 다른 사람들은 내 블로그를 보고 Hadoop과 Spark 적용할 때 도움이 되었으면 좋겠다
- 다음 포스팅에선 Hadoop과 Spark에 대해 이론적으로 다뤄보고, Docker로 배포하여 클러스터를 추가할 때, 하나씩 세팅하는 게 아니라, 자동화를 적용해볼 예정이다
'데이터 엔지니어링' 카테고리의 다른 글
| [데이터엔지니어링] 실시간 코인 데이터를 활용한 모의투자 게임 "코인예측왕" part.5 (개발과정에서의 시행착오) (0) | 2024.12.04 |
|---|---|
| [데이터엔지니어링] 실시간 코인 데이터를 활용한 모의투자 게임 "코인예측왕" part.4 (게임 소개) (0) | 2024.11.30 |
| [데이터 엔지니어링] 실시간 코인 데이터를 활용한 모의투자 게임 "코인예측왕" part.3(백엔드) (0) | 2024.11.30 |
| [데이터엔지니어링] 실시간 코인 데이터를 활용한 모의투자 게임 "코인예측왕" part.2 (데이터엔지니어링) (0) | 2024.11.29 |
| [데이터엔지니어링] 실시간 코인 데이터를 활용한 모의투자 게임 "코인예측왕" 개발 part.1 (코인 데이터 활용, 데이터 파이프라인 설계) (0) | 2024.11.27 |



