[Hadoop] YARN(Yet Another Resource Negotiator)
이번 포스팅은 Hadoop의 YARN에 대해 알아보도록 하겠다.
내가 계획한 Hadoop 포스팅은 총 3파트로 MapReduce, HDFS, YARN, 이렇게 구성된다.
2024.11.08 - [Hadoop] - [Hadoop] Apache Hadoop - MapReduce
[Hadoop] Apache Hadoop - MapReduce
글을 작성하기에 앞서..데이터 엔지니어링을 공부하기 시작하면 먼저 Hadoop ecosystem를 접하게 된다.Hadoop ecosystem을 보면 다뤄야할 프레임워크나 스킬들이 너무 많아서, 배우는 데 오래걸리겠다는
dont-make-excuses.tistory.com
2024.11.15 - [Hadoop] - [Hadoop] Apache Hadoop - HDFS(Hadoop Distributed File System)
[Hadoop] Apache Hadoop - HDFS(Hadoop Distributed File System)
이전 포스팅에서는 Hadoop과 Hadoop의 MapReduce에 대해 알아보았다.2024.11.08 - [Hadoop] - [Hadoop] Apache Hadoop - MapReduce [Hadoop] Apache Hadoop - MapReduce글을 작성하기에 앞서..데이터 엔지니어링을 공부하기 시작
dont-make-excuses.tistory.com
YARN(Yet Another Resource Negotiator) 이란?
YARN은 Hadoop의 리소스 관리와 작업 스케줄링/모니터링을 처리하는 데이터 컴퓨팅 프레임워크이다.
그렇다면, YARN이 해주는 주요 역할은 뭐가 있는 지 알아보자.
1. 리소스 관리
- 클러스터의 모든 리소스(CPU, 메모리 등)을 중앙에서 관리
- 애플리케이션이 실행되기 위해 필요한 리소스를 효율적으로 할당
- 여러 애플리케이션이 동시에 실행될 때, 자원을 조정하고 우선순위를 조율해서 공정한 리소스 사용을 보장
그럼, 여기에서 말하는 공정한 리소스 사용은 뭘까?
- 공정한 리소스 사용은 클러스터의 리소스를 여러 애플리케이션에 균등하거나 우선순위에 따라 효율적으로 분배하는 것을 의미
- 특정 애플리케이션이 리소스를 독점하지 않도록, 보장하고 리소스 사용의 효율성과 공정성을 달성하려 함
독점 방지: 클러스터에서 하나의 애플리케이션이 너무 많은 리소스를 사용하지 못하도록 제한
우선순위 기반 할당: 더 높은 우선순위를 갖고 있는 애플리케이션이 있으면, 먼저 리소스를 배정받을 수 있음
동시성 보장: 여러 애플리케이션이 동시에 실행되는 환경에서도 모든 작업이 적절한 리소스를 받을 수 있도록 보장
스케줄링 정책 기반: Capacity Scheduler(큐에 용량을 미리 정의해서 리소스를 정해진 비율만큼 배분),
Fair Scheduler(모든 애플리케이션이 동등한 리소스를 받을 수 있도록 보장),
FIFO Scheduler(먼저 제출된 애플리케이션에 먼저 리소스를 할당)
리소스 재조정: 실행 중인 애플리케이션의 리소스 요구량이 변경되거나, 새로운 애플리케이션이 실행되면 리소스를 재조정
2. 작업 스케줄링 및 실행
- 애플리케이션이 요청한 job 또는 DAG of jobs를 실행하기 위해 리소스를 스케줄링
- 각 작업이 실행되는 Container를 관리하고 실행
- 각 작업의 진행 상황을 모니터링해서 문제가 발생하면, 재시도 또는 실패 처리 수행
여기에서 말하는 DAG of job, Container는 무엇을 의미하는 걸까?
DAG (Directed Acyclic Graph) of Jobs
DAG는 방향성을 가진 비순환 그래프를 의미하고, YARN에서는 애플리케이션 작업 흐름이 DAG 구조로 표현되며,
이 흐름은 작업들 간의 의존 관계를 나타낸다.
즉, DAG of Jobs는 작업들이 어떤 순서로 실행되어야 하는지 각 작업의 선후 관계를 정의한 그래프이다.
방향성 (Directed): 작업 간의 데이터 흐름은 단방향으로 이루어지며, 이전 작업의 결과가 다음 작업의 입력으로 사용된다.
ex) job A -> job B ->job C
비순환성 (Acyclic): 작업 흐름에 순환이 존재하지 않아, 작업이 완료되면 이전 작업으로 돌아가지 않는다.
병렬 실행 가능성: 독립적인 작업은 동시에 실행될 수 있다. ex) A -> B, C -> D 여기에서 B, C는 병렬로 실행 가능
Container는 아래의 YARN Architecture에서 다뤄보도록 하겠다.
3. 클러스터 상태 모니터링
- 클러스터에 있는 모든 노드의 상태를 실시간으로 모니터링
- 문제가 발생한 노드 또는 컨테이너를 탐지하고, 대체 노드에 작업을 재배치하여 안정성을 유지
4. 애플리케이션 작업 관리
- 각 애플리케이션에 대해 AppilcationMaster를 생성해서 작업을 관리
- ApplicationMaster는 애플리케이션이 필요한 리소스를 ResourceManager에 요청
- NodeManager와 협력해서 작업을 실행하고, 실행 상태를 모니터링
- 여러 애플리케이션이 동시에 실행될 때도, 독립적으로 관리할 수 있는 구조 제공
YARN Architecture

YARN Architecture에 있는 요소들과 어떤 역할을 하는 건지 알아보자,
YARN 아키텍처의 주요 요소
1. Client
- Yarn 클러스터에서 애플리케이션을 제출한느 사용자, 애플리케이션
- Spark-submit, hadoop jar 등 명령어를 사용해서 작업을 제출
- 제출 후, 작업 상태를 모니터링 할 수 있음
2. ResourceManager
- YARN 클러스터의 중앙 관리 컴포넌트로, 리소스 할당과 작업 스케줄링을 담당
- 클러스터 전체의 리소스를 관리하며, NodeManager과 통신하여 작업 조정
- 리소스를 할당할 때, Container 라는 단위를 사용
- Scheduler, ApplicationsManager 두 가지 주요 컴포넌트로 구성
- Scheduler: 자원 할당하지만, 작업의 상태를 추적하지 않음
- ApplicationsManager: 애플리케이션 제출 처리, 첫 번째 ApplicationMaster를 시작할 때, Container를 제공함
3. NodeManager
- YARN 클러스터의 각 노드에 위치한 에이전트로 해당 노드의 리소스 CPU, 메모리를 관리함
- ResourceManager와 지속적으로 통신, 노드의 상태를 보고하고 요청된 Container를 실행함
- Container의 리소스 사용량을 모니터링하고 보고함
4. ApplicationMaster (AppMaster)
- 각 애플리케이션마다 실행되는 프로세스로 애플리케이션의 실행 관리
- ResourceManager로 리소스를 요청하고, NodeManager와 협력하여 작업 실행
- 작업 진행 상황을 모니터링하고, 필요시에 실패한 작업을 재시작함
5. Container
- YARN에서 리소스 할당의 단위,CPU 메모리 등 필요한 리소스를 정의
- NodeManager에서 생성되고 관리되며, 애플리케이션의 작업이 실행되는 환경 제공
- ApplicationMaster와 실제 작업이 Container에서 실행 됨
YARN 주요 흐름 설명
1. Job Submission (작업 제출)
- Client는 애플리케이션 또는 Task를 ResourceManager에 제출함
- ResourceManager는 제출된 작업을 처리, 애플리케이션 실행을 위한 첫 번째 ApplicationMaster를 시작할 Container 할당
2. Resource Request (자원 요청)
- ApplicationMaster는 애플리케이션의 실행에 필요한 자원을 ResourceManager에 요청
- ResourceManager는 요청된 자원을 검토하고, 적잘한 NodeManager에 Container를 할당함
3. Node Status (노드 상태 보고)
- NodeManager는 주기적으로 ResourceManager에게 리소스 사용량, 실행 중인 Container 등을 보고 함
- 이를 통해 ResourceManager는 클러스터 전체의 리소스를 효율적으로 관리
4. MapReduce Status (작업 상태 보고)
- ApplicationMaster는 Client에게 현재 애플리케이션 상태를 보고함
- 이 정보를 통해 Client는 작업의 진행 상황, 성공 여부, 실패 여부를 모니터링 할 수 있음
YARN 정리
여태까지 정보를 바탕으로 YARN을 정리해보자,
Client는 작업을 제출하고, ResourceManager는 자원 할당과 스케줄링을 담당한다.
NodeManager는 개별 노드에서 Container를 관리하고, 애플리케이션의 작업을 실행한다.
ApplicationMaster는 애플리케이션의 실행을 총괄하고, ResourceManager와 협력하여 자원을 요청, 실행한다.
Container는 작업이 실행되는 실제 환경을 제공한다.
각 흐름은 YARN의 핵심 기능인 리소스 관리와 작업 스케줄링을 통해 클러스터의 효율적인 운영을 보장한다.
YARN 아키텍처의 장점
확장성: 수천 개의 노드에서 동작할 수 있는 확장 가능한 구조를 갖는다.
유연성: MapReduce 뿐 만 아니라, 다양한 프레임워크(Spark, Flink 등)에서도 사용할 수 있다.
리소스 효율성: 자원을 동적으로 할당하고, 클러스터의 리소스를 최적으로 사용된다.
그렇다면, 이제 YARN을 직접 실행하고 Web UI로 확인해보자
YARN 실행
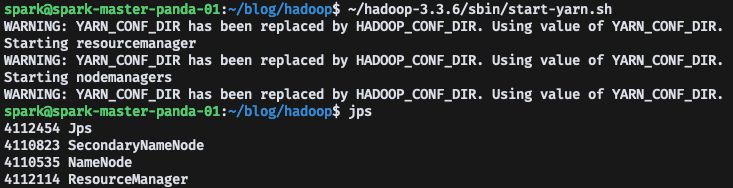
Master Node에서 start-yarn.sh로 yarn을 실행하고, jps로 ResourceManager가 실행되는 것을 확인할 수 있다.
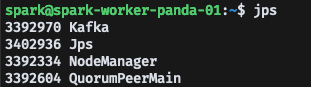
Worker Node에서는 NodeManager가 실행된 것을 확인할 수 있다.
YARN Web UI 접속
http://master-node:8088으로 접속하면 YARN Web UI에 접속할 수 있다.

YARN Web UI에서 클러스터 정보와 Running, Finished, killed 등 앱 상태도 확인할 수 있다.
Nodes에 들어가면 클러스터에 할당 된 노드들의 정보들을 볼 수 있다.
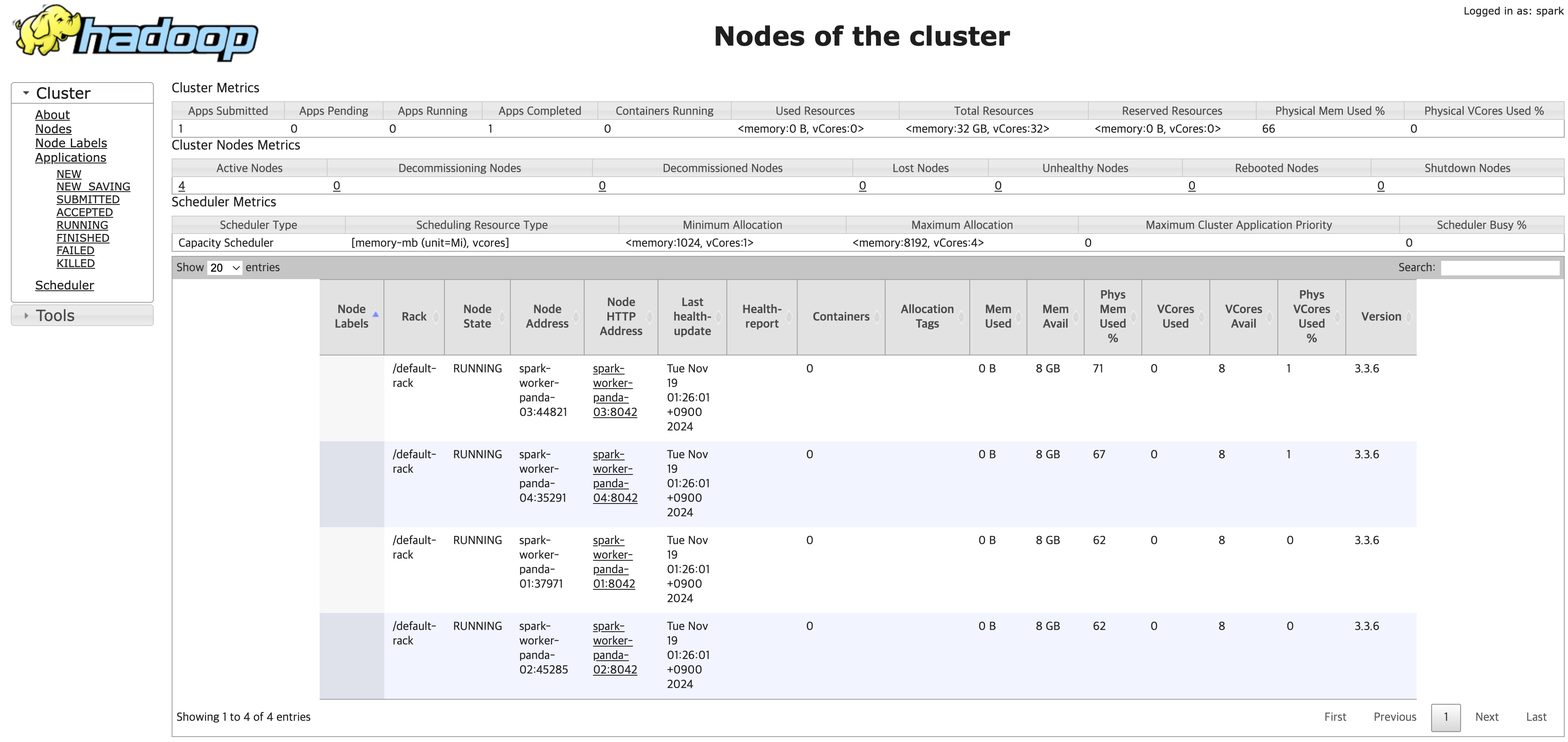
현재 Apps Runningd은 0으로 나오고 있기 때문에, yarn 애플리케이션을 실행해서 Web UI로 확인해보자.
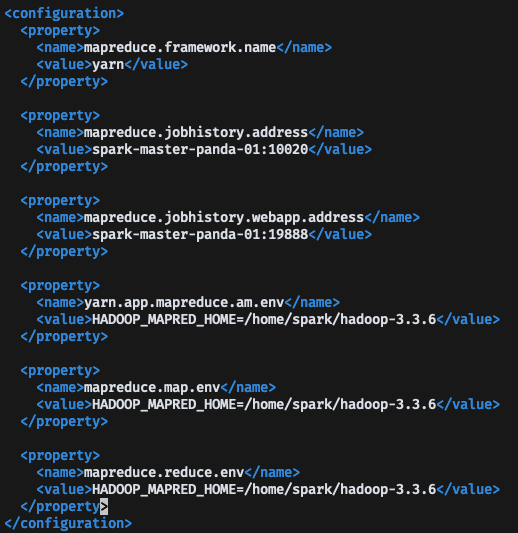
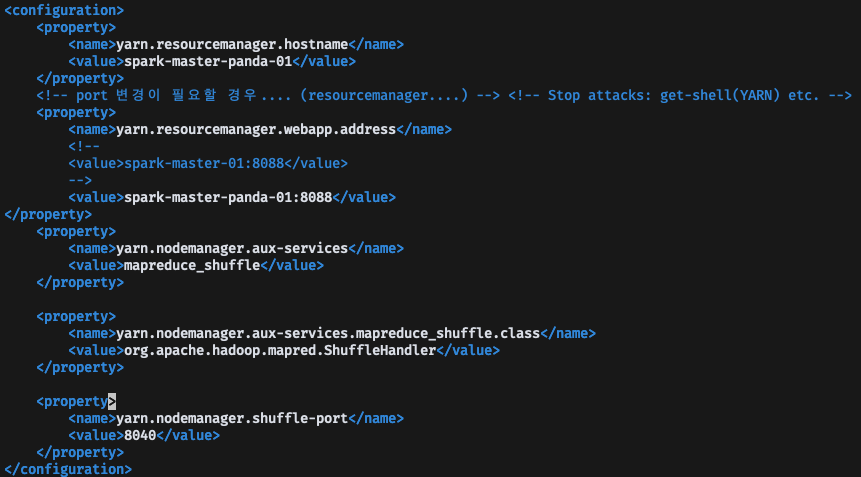
YARN 설정
먼저, Hadoop에서 YARN 설정을 해줘야한다, Hadoop/etc/hadoop 경로에 있는 mapred-site.xml, yarn-site.xml을 수정하면 된다.
YARN으로 WordCount 실행
먼저 기존에 Hadoop 명령어로 WordCount 했던 코드를 YARN으로 변경해서 실행해보자,
yarn jar wordcount.jar WordCount /input/long_text_file.txt /output
실행 했는데, 에러가 발생했다... 에러를 자세하게 살펴보자
auxService: mapreduce_shuffle does not exist Error Trouble Shooting

에러 내용을 보면 auxService: mapreduce_shuffle does not exist 에러가 발생했고, 이 에러는 YARN MapReduce 작업에서 필요한 셔플 서비스를 찾을 수 없을 때 발생한다.
분명 yarn-site.xml 설정을 해줬고, stop-yarn.sh, start-yarn.sh로 NodeManager를 재시작 해줬는데도 에러가 발생해서 당황했다.
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>이 설정을 해주면 된다고 구글링해서 찾았는데, 왜 이럴까... 했지만
답은, 마스터 노드 뿐 만아니라, 모든 워커 노드들에 적용을 해줬어야 했다.
아차 싶었고 모든 노드에 설정 파일을 수정하고, yarn을 재시작해줬다.
그리고 다시 yarn WordCount를 실행하면, 정상적인 로그를 볼 수 있다.
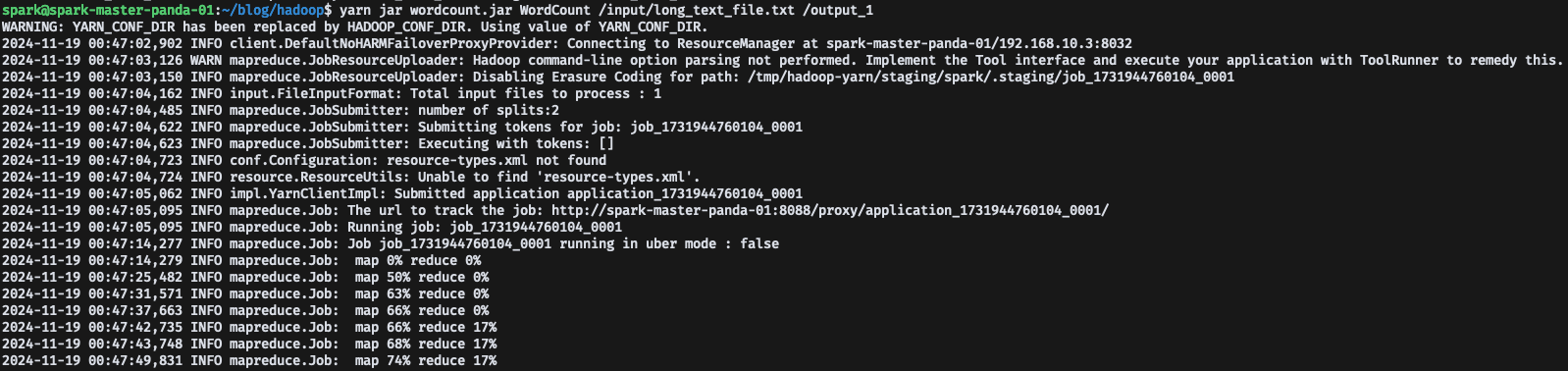
이제, YARN Web UI를 다시 살펴보자,

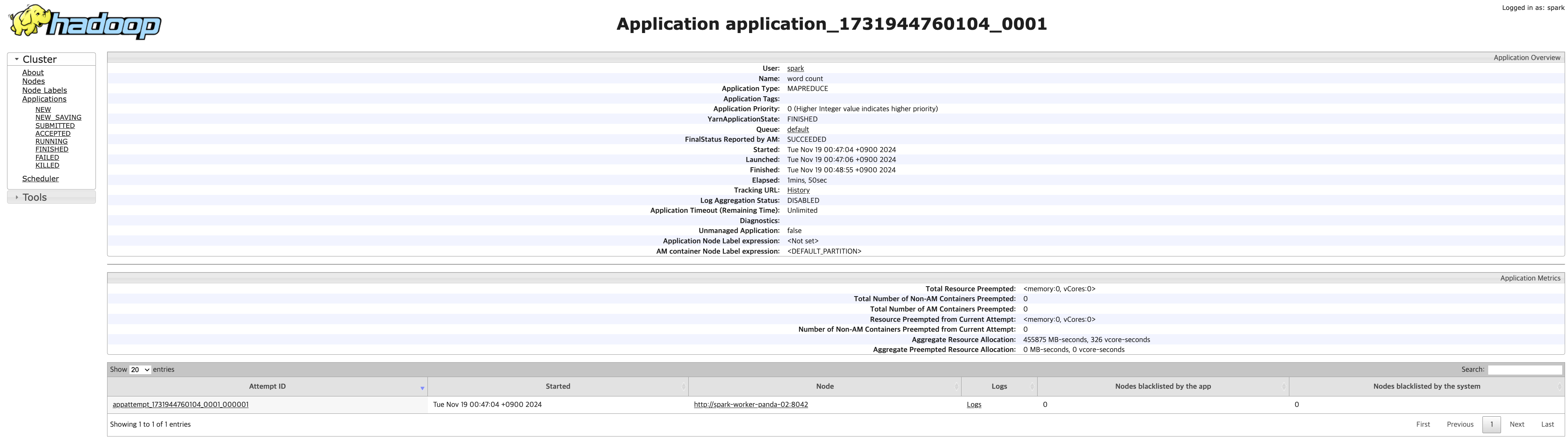
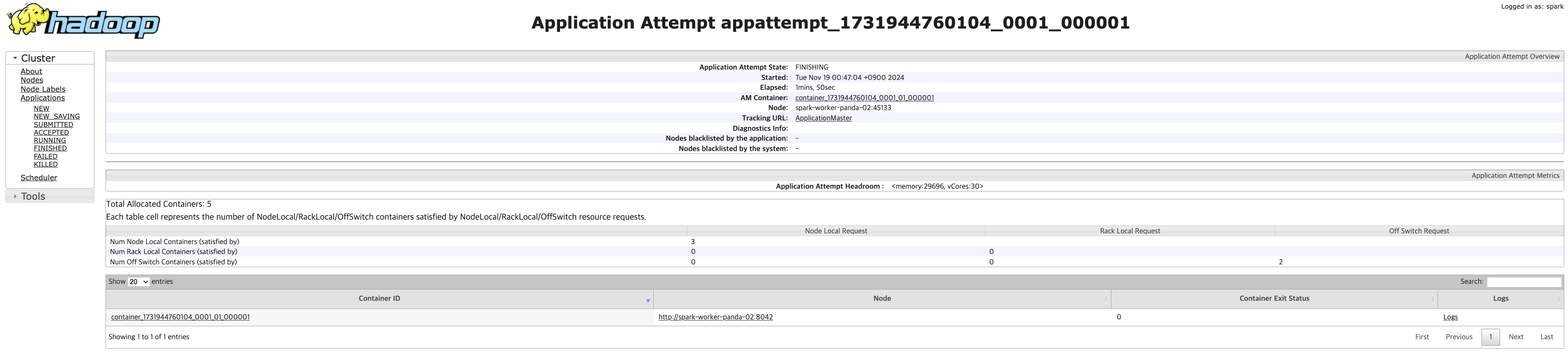
application_1731944760104_0001를 보면, spark-worker-panda-02 노드가 이 app을 실행하고 있다는 것을 확인할 수 있다.
만약 실행했을 때, 에러가 발생했거나 로그를 확인하고 싶다면, Web UI에서 로그를 확인할 수 있다.
마무리하며..
이번 YARN에 대한 글을 마무리하며, YARN의 정의와 YARN Architecture을 알아보고,
클러스터에 YARN을 실행하여 yarn으로 WrodCount를 실행시켜 Web UI에서 확인을 해보았다.
YARN 포스팅을 마지막으로, Hadoop의 주요 컴포턴트인 MapReduce, HDFS, YARN에 대해 다뤄보았다.
다음 포스팅에선 데이터엔지니어링에 많이 사용되는 Apache Spark에 대해 다뤄보도록 하겠다.